- A poor man's Common Lisp profiler (08 Mar 2016)
- CoCreate Modeling: Changing the current directory during startup (02 Nov 2015)
- Flache Hierarchien (04 Apr 2015)
- And... Action! (Part 3, 19 Sep 2009)
- And... Action! (Part 2, 08 Sep 2009)
- And... Action! (31 Aug 2009)
- A package riddle, part IV (28 Aug 2009)
- Paradigms of Artificial Intelligence Programming (25 Aug 2009)
- A package riddle, part III (22 Aug 2009)
- A package riddle, part II (20 Aug 2009)
- A package riddle (19 Aug 2009)
- STEP files for the masses (29 Jul 2009)
- Java-Forum Stuttgart (06 Jul 2009)
- Common Lisp in CoCreate Modeling (20 Jun 2009)
- European Lisp Symposium: Geeks Galore! (07 Jun 2009)
- European Lisp Symposium 2009: Keynote (03 Jun 2009)
- European Lisp Symposium 2009 (30 May 2009)
- Reasons To Admire Lisp (part 1) (16 Apr 2009)
- So long, and thanks for all the functional fish! (30 Mar 2008)
- CLR? To me, that's "Common Lisp Runtime"! (12 Mar 2008)
- In the presence of genius (06 Mar 2008)
- Common Lisp at CoCreate (29 Dec 2007)
- What's my vector, Victor? (08 Aug 2007)
- I'm just a simple property list, I didn't expect the Spanish strinquisition! (19 Jul 2007)
- "Macro" considered harmful (01 May 2007)
- Don't quote me on this (18 Mar 2006)
- Comment dit-on "knapsack" en français? (01 Mar 2006)
- Delegating closures to C# (26 Feb 2006)
- Closing in on closures (23 Feb 2006)
- Fight globalization! (18 Feb 2006)
- I'm so special (11 Feb 2006)
- Should Lisp programmers be slapped in public? (17.1.2006)
A poor man's Common Lisp profiler (08 Mar 2016)
symbol-function.
There are other profilers out there for Common Lisp, but it is not always straightforward to make them work in CoCreate Modeling which implements a subset of CLtL1 only. So who knows, maybe someone out there will actually find this useful!(in-package :clausbrod.de) (export '(profile-function unprofile-function list-profiling-results)) (let ((profile-hashtable (make-hash-table))) (defun profile-function(func) "Instrument function for profiling" ;; check if symbol-plist already contains profiler flag (unless (get func :profile-original-symbol-function) (let ((original-symbol-function (symbol-function func))) (when original-symbol-function (setf (get func :profile-original-symbol-function) original-symbol-function) ;; mark as profiled ;; install profiler code (setf (symbol-function func) (lambda(&rest r) (let ((start-time (f2::seconds-since-1970))) (unwind-protect (if r (apply original-symbol-function r) (funcall original-symbol-function)) (let ((execution-time (- (f2::seconds-since-1970) start-time)) (accum (gethash func profile-hashtable))) (if accum (setf (gethash func profile-hashtable) (+ accum execution-time)) (setf (gethash func profile-hashtable) execution-time)) (format *standard-output* "~%Execution time for ~S: ~,10F~%" func execution-time)))))) )))) (defun unprofile-function(func) "Remove profiling instrumentation for function" (let ((original-symbol-function (get func :profile-original-symbol-function))) (when (remprop func :profile-original-symbol-function) (setf (symbol-function func) original-symbol-function)))) (defun list-profiling-results() "List profiling results in order of decreasing accumulated execution times" (format *standard-output* "~%Accumulated execution times:~%") (let (table-as-list) (maphash (lambda(k v) (push (cons k v) table-as-list)) profile-hashtable) (dolist (pair (sort table-as-list #'> :key #'cdr)) (format *standard-output* "~S: ~,10F~%" (car pair) (cdr pair))))) ) (f2::win-open-console-window) (setf si::*enter-break-handler* t) (use-fast-links nil)
 To profile a function:
To profile a function:
(clausbrod.de:profile-function 'my-function)Now execute
my-function at your heart's content. Every time the function is called, the profiler measures its execution time.
When the test session is completed, accumulated execution times can be listed as follows:
(clausbrod.de:list-profiling-results)And here is how to profile all functions in a given Lisp package:
(do-external-symbols (s (find-package "FOO"))
(when (function s)
(clausbrod.de:profile-function s)))
My implementation differs almost entirely from Alex' version, which allows me to call it my own, but of course I owe thanks
to Alex for starting the discussion in the forum and posting his original inspirational code!
The code is now available as a Github project, see https://github.com/clausb/lisp-profiler. There is even a simple GUI
dialog on top of the low-level profiling code:
 The version of the code shown above uses a SolidDesigner-specific way of getting the current time in high precision. The improved
version in the Github project should work in other Lisp dialects as well. Fingers crossed.
The version of the code shown above uses a SolidDesigner-specific way of getting the current time in high precision. The improved
version in the Github project should work in other Lisp dialects as well. Fingers crossed.
CoCreate Modeling: Changing the current directory during startup (02 Nov 2015)
sd-set-current-working-directory API.
But when you call this function during startup (i.e. from
code in sd_customize, or in code loaded from there), you may find that other customization code or even CoCreate Modeling itself
changes the current directory after your code runs. This is because CoCreate Modeling remembers the directory which was current
before the user closed the last session. When you restart the application, it will try to "wake up" in precisely that working directory.
To override this behavior, here's a simple trick:
- In
sd_customize(or, preferably, in code loaded from there), register an event handler for theSD-INTERACTIVE-EVENT. - This event will be fired when startup has completed and the application becomes interactive.
- In the event handler:
- Set the current working directory as you see fit
- Unregister from the event (we want one-shot behavior here)
(in-package :de.clausbrod) (use-package :oli) (defun interactive-event-handler(&rest r) (sd-set-current-working-directory (user-homedir-pathname)) (sd-unsubscribe-event *SD-INTERACTIVE-EVENT* 'interactive-event-handler)) (sd-subscribe-event *SD-INTERACTIVE-EVENT* 'interactive-event-handler)This particular event handler sets the current working directory to the user's home directory, but this is of course just an example for a reasonable default.
Flache Hierarchien (04 Apr 2015)
node:
(defstruct node (name "" :type string) (children nil :type list))Das reicht, um einen einfachen Teilebaum abzubilden. Ein Knoten kann entweder ein einfaches Teil repräsentieren - in diesem Fall hat er nur einen Namen. Wenn es sich um eine Baugruppe handelt, hält der Knoten eine Liste von Kindknoten in
children.
(defmethod print-object ((node node) stream)
(format stream "~A [~A] "
(node-name node)
(if (node-children node) "asm" "part")))
Damit man einen node halbwegs kompakt ausgeben kann, definieren wir uns
ein zur Struktur passendes generisches print-object. Aus der etwas langatmigen Darstellung
einer Strukturinstanz wie
#S(NODE :NAME "42" :CHILDREN (#S(NODE :NAME "p42" :CHILDREN NIL)))wird dadurch
42 [asm]Testbaugruppen baut man sich einfach per Strukturliteral. Beispiel:
(let ((tree #S(NODE :NAME "a1"
:CHILDREN (#S(NODE :NAME "p1")
#S(NODE :NAME "p2")
#S(NODE :NAME "a11"
:CHILDREN (#S(NODE :NAME "p11")
#S(NODE :NAME "p12")))
#S(NODE :NAME "a12"
:CHILDREN (#S(NODE :NAME "p13")
#S(NODE :NAME "p14")))))))
Mit dieser Vorbereitung können wir nun endlich des Kollegen Codeschnippsel betrachten.
Naja, eine leicht angepasste Variante davon jedenfalls:
(defun flatten-assembly-apply-nconc(node)
(cons node
(apply #'nconc (mapcar #'flatten-assembly-apply-nconc (node-children node)))))
Ruft man flatten-assembly-apply-nconc für die obige Testbaugruppe (flatten-assembly-apply-nconc tree), erhält man
dank des von uns definierten print-object in der REPL in etwa folgendes:
(a1 [asm] p1 [part] p2 [part] a11 [asm] p11 [part] p12 [part] a12 [asm] p13 [part] p14 [part])Es entsteht also in der Tat eine flache Liste - wie schön. Sich zu verbildlichen, warum die Funktion die gewünschten Effekt hat, braucht schon einen kleinen Moment - und vielleicht auch den einen oder anderen Blick ins Lisp-Manual, um sich der genauen Funktionsweise von nconc oder mapcar zu vergewissern. Entscheidend ist unter anderem, dass Lisp-Listen letztlich Ketten von cons-Zellen sind, deren letztes Element auf
nil verweist, und dass node-children genau solche nil-Werte passend liefert, die
von mapcar und nconc auch brav durchgeschleust werden.
flatten-assembly-apply-nconc setzt das "destruktive" nconc ein, um weniger
Speicher allozieren zu müssen. Was mich gleich zu der Frage geführt hat, ob es vielleicht noch effizienter geht,
und so entstanden folgende Varianten:
(defun flatten-assembly-apply-append(node)
(cons node
(apply #'append (mapcar #'flatten-assembly-apply-append (node-children node)))))
(defun flatten-assembly-mapcan(node)
(cons node
(mapcan #'flatten-assembly-mapcan (node-children node))))
;; version using an accumulator
(defun flatten-assembly-accumulator(node &optional acc)
(cond
((null node) acc)
((listp node) (flatten-assembly-accumulator (first node) (flatten-assembly-accumulator (rest node) acc)))
((null (node-children node)) (cons node acc))
;; assembly case, i.e. a node with children
(t (cons node (flatten-assembly-accumulator (node-children node) acc)))))
Diese Varianten habe ich hintereinander in drei Lisp-Implementierungen ausgemessen, und zwar in
CLISP 2.49, Clozure CL 1.1 und
SBCL 1.2.10. Weil SBCL sich zumindest auf Mac OS
bei kurzläufigen Tests zickig
anstellt und keine Messdaten liefert, habe ich die jeweilige Testfunktion in einer Schleife 100000mal aufgerufen:
(let ((tree #S(NODE :NAME "a1"
:CHILDREN (#S(NODE :NAME "p1")
#S(NODE :NAME "p2")
#S(NODE :NAME "a11"
:CHILDREN (#S(NODE :NAME "p11")
#S(NODE :NAME "p12")))
#S(NODE :NAME "a12"
:CHILDREN (#S(NODE :NAME "p13")
#S(NODE :NAME "a121"
:CHILDREN (#S(NODE :NAME "a1211"
:CHILDREN (#S(NODE :NAME "p1211")))))
#S(NODE :NAME "p14")))))))
(defun run-test(function-symbol)
(gc)
(format t "~%Test function: ~A~%" (symbol-name function-symbol))
(print (time (dotimes (i 100000) (run-test-raw function-symbol)))))
)
(run-test 'flatten-assembly-apply-append)
(run-test 'flatten-assembly-apply-nconc)
(run-test 'flatten-assembly-mapcan)
(run-test 'flatten-assembly-accumulator)
| Variante | Lisp-Implementierung | Laufzeit (µs) | Allokation (Bytes) |
|---|---|---|---|
| flatten-assembly-apply-append | CLISP | 3173017 | 72000000 |
| flatten-assembly-apply-nconc | CLISP | 3034901 | 56000000 |
| flatten-assembly-mapcan | CLISP | 2639819 | 38400000 |
| flatten-assembly-accumulator | CLISP | 4959644 | 46400000 |
| flatten-assembly-apply-append | CCL | 70407 | 52800000 |
| flatten-assembly-apply-nconc | CCL | 54713 | 36800000 |
| flatten-assembly-mapcan | CCL | 128232 | 19200000 |
| flatten-assembly-accumulator | CCL | 20997 | 19200000 |
| flatten-assembly-apply-append | SBCL | 37000 | 52768224 |
| flatten-assembly-apply-nconc | SBCL | 25000 | 36798464 |
| flatten-assembly-mapcan | SBCL | 29000 | 19169280 |
| flatten-assembly-accumulator | SBCL | 22000 | 19169280 |
PS: Natürlich ist das hier beschriebene Problem eine Variante der Aufgabe, eine verschachtelte Liste
plattzuklopfen. http://rosettacode.org/wiki/Flatten_a_list#Common_Lisp hält einschlägige Lösungen
hierfür parat.
PS/2: In der Lisp-Implementierung HCL, die in CoCreate Modeling verwendet wird, schneiden
flatten-assembly-apply-nconc und flatten-assembly-mapcan am besten ab. Dies ist aber mit Vorbehalt
gesagt, denn in HCL musste ich den Code - mangels Compiler-Lizenz - interpretiert ablaufen lassen,
was das Performancebild vermutlich stark verfälscht.
And... Action! (Part 3, 19 Sep 2009)
Let me explain.
In the 80s, our 2D CAD application ME10 (now: CoCreate Drafting)
had become extremely popular in the mechanical
engineering market. ME10's built-in macro language was a big success factor.
Users and CAD administrators counted on it to configure their local installations,
and partners wrote macro-based extensions to add new functionality - a software
ecosystem evolved.
A typical macro-language command looked like this:
 Users didn't have to type in the full command, actually. They could start by typing in
Users didn't have to type in the full command, actually. They could start by typing in LINE
and hitting the ENTER key. The command would prompt for more input and provide hints in the
UI on what to do next, such as selecting the kind of line to be drawn, or picking points
in the 2D viewport (the drawing canvas). The example above also illustrates that commands
such as LINE RECTANGLE could loop, i.e. you could create an arbitrary amount of rectangles;
hence the need to explicitly END the command.
Essentially, each of the commands in ME10 was a domain-specific mini-language,
interpreted by a simple state machine.
The original architects of SolidDesigner (now known as CoCreate Modeling)
chose Lisp as the new extension and customization language, but they also wanted
to help users with migration to the new product. Note, however, how decidedly un-Lispy ME10's
macro language actually was:
- In Lisp, there is no way to enter just the first few parts of a "command"; users always have to provide all parameters of a function.
- Lisp functions don't prompt.
- Note the uncanny lack of parentheses in the macro example above.
- Define a special class of function symbols which represent commands
(example:
extrude). - Those special symbols are immediately evaluated anywhere
they appear in the input, i.e. it doesn't matter whether they appear inside
or outside of a form. This takes care of issue #3 above, as you no longer
have to enclose
extrudecommands in parentheses. - Evaluation for the special symbols means: Run the function code associated with the symbol. Just like in ME10, this function code (which we christened action routine) implements a state machine prompting for and processing user input. This addresses issues #1 and #2.
define-symbol-macro yet. And thus,
CoCreate Modeling's Lisp evaluator extensions were born.
To be continued...
And... Action! (Part 2, 08 Sep 2009)
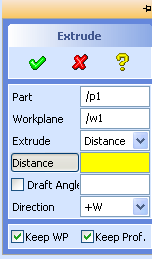 No, we don't need contrived constructs like (print extrude) to show that
No, we don't need contrived constructs like (print extrude) to show that
extrude is somehow... different from all the other kids. All we need is a simple experiment.
First, enter extrude in
CoCreate Modeling's user input line: The Extrude dialog
unfolds in all its glory, and patiently awaits your input.
Now try the same with print: All you get is an uncooperative
"Lisp error: The variable PRINT is unbound". How disappointing.
But then, the behavior for print is expected, considering the usual
evaluation rules for Common Lisp,
particularly for symbols. As a quick reminder:
- If the symbol refers to a variable, the value of the variable is returned.
- If the symbol refers to a function and occurs in the first position of a list, the function is executed.
extrude & friends belong to the symbol jet-set in CoCreate Modeling. For them,
the usual evaluation rules for functions don't apply (pun intended).
Using symbol properties
as markers, they carry a backstage pass and can party anywhere.
For members of the extrude posse, it doesn't really matter if you use them as an
atom, in the first position of a list, or anywhere else: In all cases, the function which
they refer to will be executed right away - by virtue of an extension to the evaluator
which is unique to CoCreate Modeling's implementation of Common Lisp.
You can create such upper-class symbols yourself - using a macro called defaction.
This macro is also unique to CoCreate Modeling. Functions
defined by defaction are called, you guessed it, action routines.
But why, you ask, would I want such a feature, particularly if I know that it breaks with
established conventions for Lisp evaluation?
Well, precisely because this feature breaks with the established rules.
To be continued...
And... Action! (31 Aug 2009)
print and
CoCreate Modeling commands such as extrude differ and how they
interact, you've come to the right place.
Usually, I call a dialog like this: (set_pers_context "Toolbox-Context" function) Or like this: function As soon as I add parentheses, however, the "ok action" will be called: (function)
 When highway45 talks of "functions" here, he actually means commands like
When highway45 talks of "functions" here, he actually means commands like extrude or turn. So, (set_pers_context "Toolbox-Context" extrude)? Really? Wow!
set_pers_context is an internal CoCreate Modeling function dealing with
how UI elements for a given command are displayed and where. I was floored -
first, by the fact that an end user found a need to call an internal function like this,
and second, because that magic incantation indeed works "as advertised" by highway45.
For example, try entering the following in CoCreate Modeling's user input line:
(set_pers_context "Toolbox-Context" extrude)Lo and behold, this will indeed open the
Extrude dialog, and CoCreate Modeling
now prompts for more input, such as extrusion distances or angles.
What's so surprising about this, you ask? If you've used CoCreate Modeling for a while,
then you'll know that, as a rule of thumb, code enclosed in parentheses won't prompt
for more input, but will instead expect additional parameters in the command line itself.
For example, if you run (extrude) (with parentheses!) from the user input line, Lisp will
complain that the parameter "DISTANCE is not specified". But in highway45's example, there
clearly was a closing parenthesis after extrude, and yet the Extrude command started to
prompt!
So is set_pers_context some kind of magic potion? Try this:
(print extrude)The Extrude dialog opens and prompts for input! Seems like even
print has
magic powers, even though it's a plain ol' Common Lisp standard function!
Well, maybe there is something special about all built-in functions? Let's test this out and
try a trivial function of our own:
(defun foobar() 42) (foobar extrude)Once more, the dialog opens and awaits user input! So maybe it is neither of
set_pers_context, print or foobar that is magic - but instead extrude.
We'll tumble down that rabbit hole next time.
To be continued...
A package riddle, part IV (28 Aug 2009)
(defun test() (test_dialog)) (in-package :clausbrod.de) (use-package :oli) (sd-defdialog 'test_dialog :ok-action '(display "test_dialog"))In part 3 of this mini-series, we figured out that the #: prefix indicates an uninterned symbol - and now we can solve the puzzle! Earlier, I had indicated that
sd-defdialog automatically exports dialog
names into the default package. To perform this trick, somewhere in the bowels of
the sd-defdialog macro, the following code is generated and executed:
(shadowing-import ',name :cl-user) ;; import dialog name into cl-user package (export ',name) ;; export dialog name in current package (import ',name :oli) ;; import dialog name into oli package (export ',name :oli) ;; export dialog name from the oli packageAs a consequence, the dialog's name is now visible in three packages:
- The default package (
cl-user) - Our Lisp API package (
oli) - The package in which the dialog was defined (here:
clausbrod.de)
shadowing-import inserts each of symbols into package as an internal symbol, regardless of whether another symbol of the same name is shadowed by this action. If a different symbol of the same name is already present in package, that symbol is first uninterned from package.That's our answer! With this newly-acquired knowledge, let's go through our code example one more and final time:
(defun test() (test_dialog))Upon loading this code, the Lisp reader will intern a symbol called
test_dialog into the current (default) package. As test_dialog has not
been defined yet, the symbol test_dialog does not have a value; it's just
a placeholder for things to come.
(in-package :clausbrod.de) (use-package :oli)We're no longer in the default package, and can freely use
oli:sd-defdialog without
a package prefix.
(sd-defdialog 'test_dialog :ok-action '(display "test_dialog"))
sd-defdialog performs (shadowing-import 'test_dialog :cl-user),
thereby shadowing (hiding) and uninterning the previously interned test_dialog symbol.
Until we re-evaluate the definition for (test), it will still refer to the
old definition of the symbol test_dialog, which - by now - is a) still without
a value and b) uninterned, i.e. homeless.
Lessons learned:
- Pay attention to the exact wording of Lisp error messages.
- The Common Lisp standard is your friend.
- Those Lisp package problems can be pesky critters.
(test) function would have saved
us all that hassle.
Phew.
Paradigms of Artificial Intelligence Programming (25 Aug 2009)
loop macro,
and ever since then, I knew I had to buy the book. The code contains a good amount of
Lisp macrology, and yet it is clear, concise, and so easy to follow. You can read it
like a novel, from cover to back, while sipping from a glass of pinot noir.
Impressive work.
If you've soaked up enough
Common Lisp to roughly know what lambda and defmacro do, this is the kind of
code you should be reading to take the next step in understanding Lisp. This is also
a brilliant way to learn how to use loop, by the way.
I can't wait to find out what the rest of the book is like!
Update 9/2013: Norvig's (How to Write a (Lisp) Interpreter (in Python))
is just as readable and inspirational as the loop macro code. Highly recommended.
A package riddle, part III (22 Aug 2009)
(defun test() (test_dialog)) (in-package :clausbrod.de) (use-package :oli) (sd-defdialog 'test_dialog :ok-action '(display "test_dialog"))Load the above code, run
(test), and you'll get:

In CoCreate Modeling, the
sd-defdialog macro automatically exports the name of the new
dialog (in this case, test_dialog) into the default package. Hence, you'd expect that
the function (test), which is in the default package, would be able to call that dialog!
Astute readers (and CoCreate Modeling's Lisp compiler) will rightfully scold me for using
(in-package) in the midst of a file. However, the error doesn't go away if you split up
the above code example into two files, the second of which then properly
starts with (in-package). And in fact, the problem originally manifested itself in a
multiple-file scenario. But to make it even easier for readers to run the test themselves,
I just folded the two files into one.
Lisp actually provides us with a subtle hint which I ignored so far: Did you notice
that the complaint is about a symbol #:TEST_DIALOG, and not simply TEST_DIALOG?
The #: prefix adds an important piece to the puzzle. Apparently, Lisp thinks
that TEST_DIALOG is not a normal symbol,
but a so-called uninterned symbol. Uninterned symbols are symbols which don't
belong to any Lisp package - they are homeless. For details:
- Creating Symbols (from "Common Lisp the Language", 2nd edition)
- Programming in the Large: Packages and Symbols (from Peter Seibel's excellent "Practical Common Lisp")
- The Complete Idiot's Guide to Common Lisp Packages
- Potting Soil: Colons continued - uninterned symbols
TEST_DIALOG turned into an uninterned symbol. We would have expected it to
be a symbol interned in the clausbrod.de package, which is where the dialog is defined!
Those who are still with me in this series will probably know where this is heading.
Anyway - next time, we'll finally
solve the puzzle!
A package riddle, part II (20 Aug 2009)
(defun test() (test_dialog)) (in-package :clausbrod.de) (use-package :oli) (sd-defdialog 'test_dialog :ok-action '(display "test_dialog"))Here is what happens if you save this code into a file, then load the file into CoCreate Modeling and call the
(test) function:

"The function #:TEST_DIALOG is undefined"? Let's review the code so that you can understand why I found this behavior surprising. First, you'll notice that the function
test is defined in the default Lisp package.
After its definition, we switch into a different package (clausbrod.de), in
which we then define a CoCreate Modeling dialog called test_dialog.
The (test) function attempts to call that dialog. If you've had any exposure with
other implementations of Lisp before, I'm sure you will say: "Well, of course the system
will complain that TEST_DIALOG is undefined! After all, you define it in package
clausbrod.de, but call it from the default package (where test is defined).
This is trivial! Go read
The Complete Idiot's Guide to Common Lisp Packages
instead of wasting our time!"
To which I'd reply that sd-defdialog, for practical reasons I may go into in a future blog
post, actually makes dialogs visible in CoCreate Modeling's default package. And since
the function test is defined in the default package, it should therefore have
access to a symbol called test_dialog, and there shouldn't be any error messages, right?
To be continued...
A package riddle (19 Aug 2009)
(defun test() (test_dialog)) (in-package :clausbrod.de) (use-package :oli) (sd-defdialog 'test_dialog :ok-action '(display "test_dialog"))
test.lsp, then load the file
into a fresh instance of CoCreate Modeling. Run the test function by entering (test) in
the user input line. Can you guess what happens now? Can you explain it?
To be continued...
STEP files for the masses (29 Jul 2009)
;; (C) 2009 Claus Brod ;; ;; Demonstrates how to convert models into STEP format ;; in batch mode. Assumes that STEP module has been activated. (in-package :clausbrod.de) (use-package :oli) (export 'pkg-to-step) (defun convert-one-file(from to) (delete_3d :all_at_top) (load_package from) (step_export :select :all_at_top :filename to :overwrite) (undo)) (defun pkg-to-step(dir) "Exports all package files in a directory into STEP format" (dolist (file (directory (format nil "~A/*.pkg" dir))) (let ((filename (namestring file))) (convert-one-file filename (format nil "~A.stp" filename)))))To use this code:
- Run CoCreate Modeling
- Activate the STEP module
- Load the Lisp file
- In the user input line, enter something like
(clausbrod.de:pkg-to-step "c:/allmypackagefiles")
*.pkg) file in the specified directory, a STEP file will be generated in the
same directory. The name of the STEP file is the original filename with .stp appended to it.
In pkg-to-step, the code iterates over the list of filenames returned from
(directory). For each package file, convert-one-file is called, which performs
the actual conversion:
| Step | Command |
|---|---|
| Delete all objects in memory (so that they don't interfere with the rest of the process) | delete_3d |
| Load the package file | load_package |
| Save the model in memory out to a STEP file | step_export | Revert to the state of affairs as before loading the package file | undo |
delete_3d, load_package,
step_export and undo. (These are the kind of commands which are captured in a recorder
file when you run CoCreate Modeling's recorder utility.) Around those commands, we use
some trivial Common Lisp glue code - essentially, dolist over
the results of directory. And that's all, folks
Astute readers will wonder why I use undo after the load operation rather than delete_3d
the model. undo is in fact more efficient in this kind of scenario, which is
an interesting story in and of itself - and shall be told some other day.
Java-Forum Stuttgart (06 Jul 2009)
But the remaining few of us still had a spirited
discussion, covering topics such as dynamic versus static typing, various Clojure language
elements, Clojure's Lisp heritage, programmimg for concurrency, web frameworks, Ruby on Rails,
and OO databases.
To those who stopped by, thanks a lot for this discussion and for your interest.
And to the developer from Bremen whose name I forgot (sorry): As we suspected, there is
indeed an alternative syntax for creating Java objects in Clojure.
(.show (new javax.swing.JFrame)) ;; probably more readable for Java programmers (.show (javax.swing.JFrame.)) ;; Clojure shorthand
Common Lisp in CoCreate Modeling (20 Jun 2009)
 Not many in the audience had heard about our project yet, so there were quite a few
questions after the presentation. Over all those years, we had
lost touch with the Lisp community a bit - so reconnecting to the CL matrix felt just great.
Not many in the audience had heard about our project yet, so there were quite a few
questions after the presentation. Over all those years, we had
lost touch with the Lisp community a bit - so reconnecting to the CL matrix felt just great.
 Click on the image to view the presentation. The presentation mentions LOC (lines of code) data;
those include test code.
Previous posts on the European Lisp Symposium:
Click on the image to view the presentation. The presentation mentions LOC (lines of code) data;
those include test code.
Previous posts on the European Lisp Symposium:
- European Lisp Symposium
- Europan Lisp Symposium: Keynote
- European Lisp Symposium: Geeks Galore!
- Sightrunning in Milan
European Lisp Symposium: Geeks Galore! (07 Jun 2009)

- Two days during which I didn't have to explain any of my T-shirts.
- Not having to hide my symptoms of internet deprivation on the first day of the symposium (when the organizers were still working on wifi access for everyone).
- Enjoying (uhm...) the complicated protocol dance involved in splitting up
a restaurant bill among five or six geeks. This is obviously something that
we, as a human subspecies, suck at Special shout-outs go to Jim Newton,
Edgar Gonçalves, Alessio Stalla, Francesco Petrogalli and his friend Michele.
(Sorry to those whose names I forgot; feel free to refresh my memory.)
- Meeting Lisp celebrities like Scott McKay (of Symbolics fame)
- Crashing my hotel room with four other hackers (Attila Lendvai and the amazing dwim.hu crew) who demoed both their Emacs skills and their web framework to me, sometime after midnight. (Special greetings also to Stelian Ionescu.)
European Lisp Symposium 2009: Keynote (03 Jun 2009)

- "Any bozo can write code" - this is how David Moon dismissed Scott's attempt to back up one of his designs with code which demonstrated how the design was meant to work.
- "Total rewrites are good" - Scott was the designer of CLIM, which underwent several major revisions until it finally arrived at a state he was reasonably happy with.
- "If you cannot describe something in a spec, that's a clue!" - amen, brother!
- "The Lisp community has a bad habit of building everything themselves"
- "Immutability is good" (even for single-threaded code)
- "Ruby on Rails gets it right"; only half-jokingly, he challenged the community to
build something like "Lisp on Rails". Later during the symposium, I learned that
we already have Lisp on Lines
("LoL" - I'm not kidding you here ).
- "Java + Eclipse + Maven + XXX + ... is insane!" - and later "J2EE got it spectacularly wrong"
- He reminded us that the Lisp Machine actually had C and Fortran compilers, and that it was no small feat making sure that compiled C and Fortran programs ran on the system without corrupting everybody else's memory. (I'd be curious to learn more about this.)
- Lisp code which was developed during Scott's time at HotDispatch was later converted to Java - they ended up in roughly 10x the code size.
- The QRes system at ITA has 650000 lines of code, and approx. 50 hackers are working on it. Among other things, they have an ORM layer, transactions, and a persistence framework which is "a lot less complicated than Hibernate".
- Both PLOT and Alloy were mentioned as sources of inspiration.
- Should run on a virtual machine
- Good FFI support very important
- Support for immutability
- Concurrency and parallelism support
- Optional type checking, statically typed interfaces (
define-strict-function) - "Code as data" not negotiable
European Lisp Symposium 2009 (30 May 2009)
 Other bloggers covering the event:
PS: While at lunch on Thursday, I had an interesting chat with a young
guy from Hasso-Plattner-Institut in Potsdam (Germany).
I was very impressed to hear about the many languages he already worked or experimented with.
Unfortunately, I completely forgot his name. So this is a shout-out to him:
If Google ever leads you here, I apologize for the brain leakage, and please drop
me a note!
Other bloggers covering the event:
PS: While at lunch on Thursday, I had an interesting chat with a young
guy from Hasso-Plattner-Institut in Potsdam (Germany).
I was very impressed to hear about the many languages he already worked or experimented with.
Unfortunately, I completely forgot his name. So this is a shout-out to him:
If Google ever leads you here, I apologize for the brain leakage, and please drop
me a note!
Reasons To Admire Lisp (part 1) (16 Apr 2009)

s_expression = atomic_symbol / "(" s_expression "."s_expression ")" / list
list = "(" s_expression < s_expression > ")"
atomic_symbol = letter atom_part
atom_part = empty / letter atom_part / number atom_part
letter = "a" / "b" / " ..." / "z"
number = "1" / "2" / " ..." / "9"
empty = " "
Now compare the above to, say,
Java.
(And yes, the description above doesn't tell the whole story since it doesn't cover any
kind of semantic aspects. So sue me.)
Oh, and while we're at it: Lisp Syntax Doesn't Suck,
says Brian Carper, and who am I to disagree.
So there.
So long, and thanks for all the functional fish! (30 Mar 2008)
;; -*-Lisp-*-
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Description: Wrapper to run Frank Buss' functional geometry code
;; in CoCreate Modeling
;; Author: Claus Brod
;; Language: Lisp
;;
;; (C) Copyright 2008 Claus Brod, all rights reserved
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;;
(in-package :clausbrod.de)
(use-package :oli)
(export '(plot-escher))
;; Allow using lambda without quoting it via #' first
;; (No longer required in CoCreate Modeling 2008 and later.)
(defmacro lambda (&rest body)
`(function (lambda ,@body)))
(defparameter *our-loadpath* *load-truename*)
(load (format nil "~A/functional.lsp"
(directory-namestring *our-loadpath*)))
;; Modeling-specific plotter function
(defun plot-annotation (p)
(let ((tempfile (format nil "~A/test.mac" (oli:sd-inq-temp-dir)))
(scale 500.0))
(startup::activate-annotation)
(with-open-file (s tempfile
:direction :output :if-exists :supersede)
(format s "line~%")
(dolist (line (funcall p '(0 0) '(1 0) '(0 1)))
(destructuring-bind ((x0 y0) (x1 y1)) line
(format s " ~D,~D ~D,~D~%"
(* scale (float x0))
(* scale (float y0))
(* scale (float x1))
(* scale (float y1)))))
(format s "end"))
(oli:sd-execute-annotator-command
:cmd (format nil "input '~A'" tempfile))
(docu::docu_vp :fit_vp)
(delete-file tempfile)))
;; Shortcut for the Escher fish drawing
(defun plot-escher()
(plot-annotation *fishes*))
The loader code adds the definition for the lambda macro
which is missing so far in CoCreate Modeling, loads Frank's code, and then adds a
plotter function which creates output in a 2D Annotation window.
Usage instructions:
- Download Frank's code from his site
and save it as
functional.lsp. - Download the loader code and save it into the same directory.
- Load the loader Lisp code into CoCreate Modeling 2007 or higher.
- In the user input line, enter
(clausbrod.de:plot-escher)
CLR? To me, that's "Common Lisp Runtime"! (12 Mar 2008)
In other words, I want Common Lisp to become a mainstream language - which it arguably
isn't, even though pretty much everybody agrees about its power and potential.
One way to acquire mainstream super-powers is to team up with one of the
planet's most potent forces in both software development and marketing: Microsoft. This
is the strategic reason for my proposal. Yes, I know, many Lisp gurus and geeks out
couldn't care less about Microsoft and the Windows platform, or even shudder at the
thought. But there are also tactical and technical reasons, so bear with me for a minute
before you turn on your flamethrowers.
When I say Microsoft, I really mean .NET and its Common Language Runtime. Well, that's
what they say is how to spell out CLR. But I claim that the L could just
as well stand for Lisp, as the CLR, particularly in conjunction with the
Dynamic Language Runtime
extensions which Microsoft is working on, is a suspiciously suitable platform to build an
implementation of Common Lisp upon: Not only does it provide a renowned garbage collector
(designed by former Lisp guru
Patrick
Dussud)
and a rich type system, it also has extensive reflection and code generation support,
and - through the DLR - fast dynamic function calls,
AST processing and compilation,
debugger integration, REPL support, and all that jazz. It's no coincidence
that languages such as C# and even VB.NET are picking up new dynamic language
features with every new release, and that Microsoft has even added a new functional
language, F#, to the set of languages which are (or will be)
fully integrated into Visual Studio.
The wave is coming in, and we better not miss it!
Best of all, it's not just about Windows anymore: The DLR and IronPython also
run on top of
Mono. Mono is available for Linux, Solaris, Mac OS X,
various BSD flavors as well as for Windows, so layering Common Lisp on
top of the CLR doesn't limit us to the Windows platform at all!
Note that I explicitly said "Common Lisp". I think that it's vital
for an implementation on top of the CLR/DLR to be truly standards-compliant. I am not alone
in this belief: In the
IronPython and IronRuby
projects, Microsoft went to great lengths to make sure that the implementations are true
to the original language.
What would this buy us? Well, one recurring and dominant theme in discussions about
the viability of Lisp as a mainstream language is the perceived or real
lack of actively maintained libraries and tools. With the approach I'm outlining,
we could still run all those excellent existing
Common Lisp libraries
and projects
out
there,
but we'd also be able to use the huge body of code both in the .NET framework
itself and in third-party .NET components. Common Lisp code could seamlessly
call into a library written in, say, C#, and VB.NET programmers would be able
to consume Common Lisp libraries!
Taking it a little further, we could also integrate with Visual Studio. Where I work,
it would make all the difference in the world if we could edit, run and debug
our Lisp code from within Visual Studio. I'm convinced that this would
attract a large new group of programmers to Common Lisp. Hordes of them, in fact
Yes, I know about SLIME and
Dandelion and
Cusp, and I'm perfectly aware that
Emacs will simultaneously
iron your shirts, whistle an enchanting tune, convincingly act on your behalf
in today's team phone conference, and book flights to the Caribbean
while compiling, debugging, refactoring and possibly even writing all your
Lisp code for you in the background. Still, there's a whole
caste of programmers who never felt any desire to reach beyond the confines
of the Visual Studio universe, and are perfectly happy with their IDE,
thank you very much. What if we could sell even those programmers on
Common Lisp? (And yes, of course you and I could continue to use our
beloved Emacs.)
Now, all these ideas certainly aren't original. There are a number of projects
out there born out of similar motivation:
- L Sharp .NET - a Lisp-based scripting language for .NET by Rob Blackwell
- Yarr - Lisp-based scripting language for .NET based on L Sharp
- dotLisp - a Lisp dialect for .NET, written by Rich Hickey (of Clojure fame)
- Rich Hickey mentioned in a presentation that the original versions of Clojure were actually written to produce code for the CLR
- IronLisp - Lisp on top of the DLR, initiated by Llewellyn Pritchard, who later decided to tackle IronScheme instead
- There's a even a toy Common Lisp implementation by Microsoft which they shipped as a sample in the .NET Framework SDK (and now as part of the Rotor sources)
- Joe Marshall has an interesting project which looks like Lisp implemented in C#.
- LispSharp is a CLR-based Lisp compiler (Mirko Benuzzi)
- ClearLisp is another CL dialect written in C# by Jan Tolenaar.
- A LISP/Scheme language for .NET (Adam Milazzo)
- CLearSharp, by Ola Bini
- Joe Duffy's Sencha project
- VistaSmalltalk may not sound like Lisp, but it actually contains a Lisp engine (implemented in C#), and according to the architecture notes I found, Smalltalk is implemented on top of Lisp.
- CLinNET, by Dan Muller
- CarbonLisp, by Eric Rochester
- MBase, a "metaprogramming framework" providing a Lisp-like definition language
- Sohail Somani experiments with .NET IL generation from Lispy syntax
- RDNZL - .NET interop layer for Common Lisp (Edi Weitz)
- FOIL - Foreign object interface for Lisp (i.e. an interop layer) on top of both the JVM and the CLR, by Rich Hickey (again!) and Eric Thorsen
In the presence of genius (06 Mar 2008)
 I sure hope I'll have a chance to meet Kent one day!
I sure hope I'll have a chance to meet Kent one day!
Common Lisp at CoCreate (29 Dec 2007)

 But much of what is said
in the article about Lisp still applies.
The HP Journal article concluded:
But much of what is said
in the article about Lisp still applies.
The HP Journal article concluded:
Common Lisp is also used as a user accessible extension language for HP PE/SolidDesigner. It is a standardized, open programming language, not a proprietary one as in HP PE/ME10 and PE/ME30, and the developers of HP PE/SolidDesigner believe that this will prove to be an immense advantage.SolidDesigner was the original product name; ME10 and ME30 were predecessor products which implemented their own little macro interpreters. Back then, we were a bit cautious about the potential benefits we'd reap, as the product was still in its early days. By now, however, we can say that Common Lisp was a key factor in helping a fairly small team of developers keep pace with the big guns in the industry, due to all the well-known productivity features in Lisp, such as macros, the REPL, or automatic memory management. The HP Journal article describes how we use macros to define a domain-specific language called action routines, which are state machines which guide users through commands. Later, we extended that concept by automatically generating UI for those commands: Using the sd-defdialog macro, application developers can implement full-blown commands in just a few lines of code, without having to write any (or at least hardly any) code for services such as:
- Automatic "macro recording" of commands
- Context-sensitive online help
- UNDO support
- Command customization (commands can be started from toolbars, menus, a user input line, or from our "taskbar")
- Sequence control (dependencies of user inputs on other input)
- UI creation and layout
- Adherence to UI style guides
- Graphical feedback both in the UI and in 3D graphics windows
- Type and range checks for input data
- Automatic unit conversions (imperial to metric etc.)
- Prompting
What's my vector, Victor? (08 Aug 2007)
(line :two_points 100,100 0,0)Common Lisp connoisseurs will notice that this is decidedly non-standard behavior. Those commas aren't supposed to be there; instead, commas serve their purpose in list quoting, particularly in macro definitions. (For a refresher, check out The Common Lisp Cookbook - Macros and Backquote.) And in any other implementation of Lisp, this code would indeed result in an error message such as "comma is illegal outside of backquote". OneSpace Modeling's embedded Lisp, however, will notice a pair of literal numbers and assume that what the user really meant to specify is a structure of type
gpnt2d, which holds x and y slots for the coordinates. And so
what is really evaluated is more like this:
(line :two_points (oli:make-gpnt2d :x 100 :y 100) (oli:make-gpnt2d :x 0 :y 0))
oli is the Lisp package which exports the gpnt2d structure as well as its accessor
and constructor functions.
This explicit syntax is actually required whenever you need to specify coordinates
using non-literals, such as when the actual coordinates are the results of
mathematical calculations. For instance, vector syntax is not recognized
in the following:
(line :two_points (+ 50 50),100 0,0)Now you'll get the expected error message reporting that "a comma has appeared out of a backquote". To make this work, you'd have to say:
(line :two_points (oli:make-gpnt2d :x (+ 50 50) :y 100) 0,0)But despite this limitation, the vector syntax extension was tremendously important for us: Coordinates can be entered in all kinds of places in the user interface where casual users would never suspect that what they are entering is actually thrown into funny engines which the propellerheads at CoCreate call "the Lisp reader" and "the Lisp evaluator".

I'm just a simple property list, I didn't expect the Spanish strinquisition! (19 Jul 2007)
(setf (get 'some-symbol some-indicator) some-value)And to inquire a symbol property, you just say something like
(get 'some-symbol some-indicator).
some-indicator can basically be any type, and so I wasn't sure what my
co-worker meant when he said that he couldn't get strings to work, until
he explained the details to me: He was calling some Lisp-based API
function in our product, and that function returns a property list.
Unfortunately, that property list was special in that somebody had
stuffed a string into it as an indicator, and so the property list
looked somehow like this:
("foo" 42 "bar" 4711)
And indeed, if you now try to inquire the "foo" property using
(get 'some-symbol "foo"), all you get is - nil.
To retrieve a property value, get walks the list and compares each
indicator in the list with "foo" (in this example) - using eq.
From which we can immediately conclude:
- The correct spelling of "property list" is p-e-r-f-o-r-m-a-n-c-e p-r-o-b-l-e-m, as each lookup requires traversing potentially all of the list.
-
eqchecks for object equality, not just value equality. Which means that things like literal (!) strings or characters cannot be indicators!
(get 'some-symbol "foo"), and that "foo" string literal
creates a new string object. While that new object happens to have
the same value as the "foo" string in the property list, it is not the same object.
Indeed, the
Common Lisp HyperSpec
is quite clear on that topic:
"Numbers and characters are not recommended for use as indicators in
portable code since get tests with
eq rather than eql, and
consequently the effect of using such indicators is implementation-dependent."
It all boils down to the simple fact that (eq "foo" "foo") returns nil.
Now hopefully we can fix the API which returned those inadequate property
lists to my co-worker's code, but his code also needs to run in older
and current installations, and so he needed a workaround of some sort.
His first idea was to get the property list and fix it up in a preprocessing
step before using get or getf for lookup, i.e. something like this:
(defun fix-plist(plist old-indicator new-indicator)
(let ((cnt 0))
(mapcar
#'(lambda(item)
(incf cnt)
(if (and (oddp cnt) (equal item old-indicator))
new-indicator item))
plist)))
(setf my-symbol 42)
(setf (get 'my-symbol "indicator") "value") ;; mess up plist
(print (get 'my-symbol "indicator")) ;; returns NIL
(print (getf (fix-plist (symbol-plist 'my-symbol) "indicator" :indicator) :indicator))
This works, kind of - but it is actually quite ugly. Sure, with this code, we should be
able to safely move ahead, especially since I also closed that office window in the
meantime, but still: I really hope I'm missing something here. Any other ideas out there?
"Macro" considered harmful (01 May 2007)
- In Lisp, a macro is a piece of code defined by defmacro. Macros in Lisp are a clever way to extend the language. If you want to learn more about this (or about Common Lisp in general, in fact), I recommend Peter Seibel's "Practical Common Lisp" - here's the section on macros.
- CoCreate's 2D package, OneSpace Drafting, has a built-in macro interpreter which can be used to customize and extend the product. Since many OneSpace Drafting migrate from 2D to 3D, i.e. to OneSpace Modeling, they tend to take their nomenclature with them, and so they often call pieces of Lisp customization code a "macro", too.
- In many software packages, users can record the interaction with the product and save the result into files, which are then often called macro files. OneSpace Modeling's recorder is such a mechanism, and so using the word "macro" is kind of natural for many users.
sd-defdialog which is provided by the "Integration Kit" library which
ships with OneSpace Modeling. This API is, in fact, implemented
using defmacro, i.e. sd-defdialog is itself a Lisp macro. So if a user
writes code which builds on sd-defdialog and then calls the result a macro,
he's actually not that far from the truth - although, of course, still
incorrect.
Don't quote me on this (18 Mar 2006)
Let us assume that I'm a little backward and have a peculiar fondness for the DOS command shell. Let us further assume that I also like blank characters in pathnames. Let us conclude that therefore I'm hosed. But maybe others out there are hosed, too. Blank characters in pathnames are not exactly my exclusive fetish; others have joined in as well (C:\Program Files,
C:\Documents and Settings). And when using software, you might be running
cmd.exe without even knowing it. Many applications can run external helper
programs upon user request, be it through the UI or through the application's
macro language.
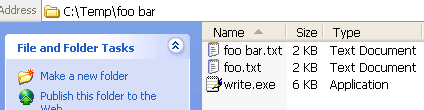 The test environment is a directory
The test environment is a directory c:\temp\foo bar which contains
write.exe (copied from the Windows system directory) and two text files, one of
them with a blank in its filename.
Now we open a DOS shell:
C:\>dir c:\temp\foo bar
Volume in drive C is IBM_PRELOAD
Volume Serial Number is C081-0CE2
Directory of c:\temp
File Not Found
Directory of C:\
File Not Found
C:\>dir "c:\temp\foo bar"
Volume in drive C is IBM_PRELOAD
Volume Serial Number is C081-0CE2
Directory of c:\temp\foo bar
03/18/2006 03:08 PM <DIR> .
03/18/2006 03:08 PM <DIR> ..
01/24/2006 11:19 PM 1,516 foo bar.txt
01/24/2006 11:19 PM 1,516 foo.txt
03/17/2006 09:44 AM 5,632 write.exe
3 File(s) 8,664 bytes
2 Dir(s) 17,448,394,752 bytes free
Note that we had to quote the pathname to make the DIR command work.
Nothing unusual here; quoting is a fact of life for anyone out there
who ever used a DOS or UNIX shell.
Trying to start write.exe by entering c:\temp\foo bar\write.exe in the
DOS shell fails; again, we need to quote:
And if we want to loadC:\>"c:\temp\foo bar\write.exe"
foo bar.txt into the editor, we need to quote
the filename as well:
Still no surprises here. But let's suppose we want to run an arbitrary command from our application rather than from the command prompt. The C runtime library provides the system() function for this purpose. It is well-known that under the hoodC:\>"c:\temp\foo bar\write.exe" "c:\temp\foo bar\foo bar.txt"
system actually runs cmd.exe to do its job.
#include <stdio.h>
#include <process.h>
int main(void)
{
char *exe = "c:\\temp\\foo bar\\write.exe";
char *path = "c:\\temp\\foo bar\\foo bar.txt";
char cmdbuf[1024];
_snprintf(cmdbuf, sizeof(cmdbuf), "\"%s\" \"%s\"", exe, path);
int ret = system(cmdbuf);
printf("system(\"%s\") returns %d\n", cmdbuf, ret);
return 0;
}
When running this code, it reports that system() returned 0, and write.exe
never starts, even though we quoted both the name of the executable and
the text file name.
What's going on here? system() internally runs cmd.exe like this:
Try entering the above in the command prompt: No editor to be seen anywhere! So when we runcmd.exe /c "c:\temp\foo bar\write.exe" "c:\temp\foo bar\foo bar.txt"
cmd.exe programmatically, apparently it parses its input
differently than when we use it in an interactive fashion.
I remember this problem drove me the up the freakin' wall when I first encountered
it roughly two years ago. With a lot of experimentation, I found the right
magic incantation:
Note that I quoted the whole command string another time! Now the executable actually starts. Let's verify this in the command prompt window: Yes, something like_snprintf(cmdbuf, sizeof(cmdbuf), "\"\"%s\" \"%s\"\"", exe, path); // originally: _snprintf(cmdbuf, sizeof(cmdbuf), "\"%s\" \"%s\"", exe, path);
cmd.exe /c ""c:\temp\foo bar\write.exe" "c:\temp\foo bar\foo bar.txt""
does what we want.
I was reminded of this weird behavior when John Scheffel, long-time user of our flagship
product OneSpace Designer Modeling and maintainer of the international
CoCreate user forum, reported funny
quoting problems when trying to run executables from our app's built-in Lisp interpreter.
John also found the solution and documented it in a Lisp version.
Our Lisp implementation provides a function called sd-sys-exec, and you need to
invoke it thusly:
Kudos to John for figuring out the Lisp solution. Let's try to decipher all those quotes and backslashes in the(setf exe "c:/temp/foo bar/write.exe") (setf path "c:/temp/foo bar/foo bar.txt") (oli:sd-sys-exec (format nil "\"\"~A\" \"~A\"\"" exe path))
format statement.
Originally, I modified his solution slightly
by using ~S instead of ~A in the format call and thereby saving one level
of explicit quoting in the code:
(format nil "\"~S ~S\"" exe path))This is much easier on the eyes, yet I overlooked that the
~S format specifier
not only produces enclosing quotes, but also escapes any backslash characters
in the argument that it processes. So if path contains a backslash (not quite
unlikely on a Windows machine), the backslash will be doubled. This works
surprisingly well for some time, until you hit a UNC path which already starts
with two backslashes. As an example, \\backslash\lashes\back turns into
\\\\backslash\\lashes\\back, which no DOS shell will be able to grok anymore.
John spotted this issue as well. Maybe he should be writing these blog entries,
don't you think?
From those Lisp subtleties back to the original problem:
I never quite understood why the extra level of quoting is necessary for
cmd.exe, but apparently, others have been in the same mess before. For example,
check out
this XEmacs code
to see how complex correct quoting can be. See also an online version of
the help pages for CMD.EXE
for more information on the involved quoting heuristics applied by the shell.
PS: A very similar situation occurs in OneSpace Designer Drafting as well
(which is our 2D CAD application). To start an executable write.exe in a directory
c:\temp\foo bar and have it open the text file c:\temp\foo bar\foo bar.txt,
you'll need macro code like this:
LET Cmd '"C:\temp\foo bar\write.exe"'
LET File '"C:\temp\foo bar\foo bar.txt"'
LET Fullcmd (Cmd + " " + File)
LET Fullcmd ('"' + Fullcmd + '"') { This is the important line }
RUN Fullcmd
Same procedure as above: If both the executable's path and the path of
the data file contain blank characters, the whole command string which
is passed down to cmd.exe needs to be enclosed in an additional
pair of quotes...
PS: See also http://blogs.msdn.com/b/twistylittlepassagesallalike/archive/2011/04/23/everyone-quotes-arguments-the-wrong-way.aspx
and http://daviddeley.com/autohotkey/parameters/parameters.htm
http://xkcd.com/1638/
-- ClausBrod - 27 Mar 2016
Comment dit-on "knapsack" en français? (01 Mar 2006)
This week, a customer of our software asked a seemingly innocent question; given a set of tools of various lengths, he wanted to find subsets of those tools which, when combined, can be used to manufacture a screw of a given length. From the description, I deduced that we were talking about a variation of the subset sum problem which is a special case of the knapsack problem. Faint memories of my time at university arose; I couldn't resist the weird intellectual tickle. Or maybe it was just the beginning of my pollen allergy for this year Anyway, I searched high and low on my
quest to reacquire long-lost knowledge.
One of the weirder search results was a TV show called
Des chiffres et des lettres
which has been running for ages now on French TV. In that show, they
play a game called "Le compte est bon" which is actually a variation
of the subset sum problem! The candidates are supposed to solve this puzzle
in about a minute or so during the show. Wow - these French guys must
be math geniuses!
Anyway, I couldn't help but try a subset sum algorithm in Lisp.
I ran it both using CLISP and the implementation of Lisp provided in
CoCreate OneSpace Modeling. I started to collect
some benchmark results for CLISP, comparing interpreted and compiled
code to get a better feeling for the kind of improvements I can expect
from the CLISP compiler. In the case of CLISP, the compiler improves
runtime by roughly an order of magnitude. See the discussion of the algorithm for detailled results.
https://xkcd.com/287/
-- ClausBrod - 01 Sep 2017
Delegating closures to C# (26 Feb 2006)
Last time, I looked at how closures work in Lisp, and tried to mimick them in C++ (without success) using function objects. To recap, a closure can be thought of as:- A function pointer referring to the code to be executed
- A set of references to frames on the heap, namely references to all bindings of any free variables which occur in the code of the function.
class TestDelegate
{
public delegate void MyDelegate();
public MyDelegate GetDelegate()
{
string s = "Hiya";
return delegate() { Console.WriteLine(s); }; // anon delegate
}
static void Main(string[] args)
{
TestDelegate p = new TestDelegate();
MyDelegate anonDel = p.GetDelegate();
anonDel();
}
}
In the anonymous delegate, s is a free variable; the code compiles because
the delegate refers to the definition of s in the surrounding code.
If you run the above code, it will indeed print "Hiya", even though
we are calling the delegate from Main, i.e. after we have left
GetDelegate() which assigns that string to a local variable.
This is quite cool, considering that the .NET CLR uses a conventional
stack and probably wasn't designed to run Lisp or Scheme all day. How do they
do this?
Let's look at the disassembled code of GetDelegate() (using .NET Reflector,
of course):
public TestDelegate.MyDelegate GetDelegate()
{
TestDelegate.<>c__DisplayClass1 class1 = new TestDelegate.<>c__DisplayClass1();
class1.s = "Hiya";
return new TestDelegate.MyDelegate(class1.<GetDelegate>b__0);
}
So the compiler morphed our code while we were looking the other way!
Instead of assigning "Hiya" to a local variable, the code instantiates
a funky <>c__DisplayClass1 object, and that object apparently has a
member called s which holds the string. The <>c__DisplayClass1 class
also has an equivalent of the original GetDelegate function, as it seems.
Hmmm.... very puzzling - let's look at the definition of that proxy
class now:
[CompilerGenerated]
private sealed class <>c__DisplayClass1
{
// Methods
public <>c__DisplayClass1();
public void <GetDelegate>b__0();
// Fields
public string s;
}
public void <GetDelegate>b__0()
{
Console.WriteLine(this.s);
}
Aha, now we're getting somewhere. The compiler moved the code in the anonymous delegate
to the function <>c__DisplayClass1::<GetDelegate>b__0. This function
has access to the field s, and that field is initialized by the
compiler when the proxy object is instantiated.
So when the C# compiler encounters an anonymous delegate,
it creates a proxy object which holds all "bindings" (in Lisp terminology)
of free variables in the code of the delegate. That object is kept on the heap
and can therefore outlive the original GetDelegate(), and that is why we
can call the delegate from Main and still print the expected string
instead of referring to where no pointer has gone before.
I find this quite a cool stunt; I'm impressed by how the designers of C# are
adding useful abstractions to the language. Lisp isn't the only language which
supports closures, and maybe wasn't even the first, but I'm pretty sure that
the folks at Microsoft were probably influenced by either Lisp (or Scheme)
while developing anonymous delegates. It is amazing how such an old
language continues to inspire other languages to this day.
And that is, after reading a couple of good books and enlightening articles,
what I understood about closures. Now, as a long-time boneheaded C++ programmer, I might
have gotten it all wrong, and this blog entry is actually one way to test
my assumptions; if my views are blatantly misleading, then hopefully somebody will
point this out. (Well, if anybody reads this at all, of course.)
What a simple and amazing concept those closures really are! I only had to
shed all my preconceptions about the supposedly one and only way to call and execute
functions and how to keep their parameters and variables on a stack...
Closures are definitely very handy in all situations where callbacks are registered.
Also, I already alluded to the fact that you could possibly build an object concept on top of
closures in Lisp. And doesn't "snapshot of a function in execution" sound
frighteningly close to "continuation"
or "coroutines"? (Answer: Yes, kind of, but not quite. But that's a different story.)
I'm still trying to learn what closures do and how to best apply them in practice.
But that doesn't mean they are constructs for the ivory tower: Knowing about them
helped me only recently to diagnose and explain
what originally looked like a memory leak in some Lisp test code that we had written.
The final word of the jury is still out, but this is probably not a real leak,
rather a closure which holds on to the binding of a variable, so that the garbage
collector cannot simply free the resources associated with that variable.
Closing in on closures (23 Feb 2006)
The other day, I battled global variables in Lisp by using this construct:
(let ((globalFoo 42))
(defun foobar1()
(* globalFoo globalFoo))
(defun foobar2(newVal)
(setf globalFoo newVal))
)
globalFoo is neither declared nor bound within the functions foobar1 or foobar2;
it is a free variable. When Lisp encounters such a variable, it will search
the enclosing code (the lexical environment) for a binding of the variable; in
the above case, it will find the binding established by the let statement, and
all is peachy.
globalFoo's scope is limited to the functions foobar1 and foobar2;
functions outside of the let statement cannot refer to the variable.
But we can call foobar1 and foobar2 even after returning from the let
statement, and thereby read or modify globalFoo without causing a runtime
errors.
Lisp accomplishes this by creating objects called closures. A closure is a
function plus a set of bindings of free variables in the function. For
instance, the function foobar1 plus the binding of globalFoo to a
place in memory which stores "42" is such a closure.
To illustrate this:
> (load "closure.lsp") ;; contains the code above T > globalFoo ;; can we access the variable? *** Variable GLOBALFOO is unbound > (foobar1) ;; we can't, but maybe foobar1 can 1764 > (foobar2 20) ;; set new value for globalFoo 20 > (foobar1) 400Hmmm - what does this remind you of? We've got a variable which is shared between two functions, and only those functions have access to the variable, while outside callers have not... he who has never tried to encapsulate data in an object shall cast the first pointer!
Proofreading this, I realize that the simple Lisp code example is probably not too instructive; I guess closures really start to shine when you let functions return anonymous functions with free variables in them. Hope to come up with better examples in the future.So this is how closures might remind us of objects. But let's look at it from a different angle now - how would we implement closures in conventional languages? Imagine that while we invoke a function, we'd keep its parameters and local variables on the heap rather than on the stack, so instead of stack frames we maintain heap frames. You could then think of a closure as:
- A function pointer referring to the code to be executed
- A set of references to frames on the heap, namely references to all bindings of any free variables which occur in the code of the function.
typedef bool (*fncptr)(int, float);
fncptr foobar_fnc; // declaration
class FunctionObject {
private:
int m_i;
float m_f;
fncptr m_fnc;
public:
FunctionObject(fncptr fnc, int i, float f) : m_fnc(fnc), m_f(f), m_i(i) {}
bool operator() { m_fnc(m_i, m_f); }
};
FunctionObject fo(foobar_fnc, 42, 42.0);
FunctionObject captures a snapshot of a function call with its parameters.
This is useful in a number of situations, as can be witnessed by trying to enumerate
the many approaches to implement something like this in C++ libraries such as
Boost; however, this is not a closure. We're "binding"
function parameters in the function object - but those are, in the sense described
earlier, not free variables anyway. On the other hand, if the code of the function
referred to by the FunctionObject had any free variables, the FunctionObject
wouldn't be able to bind them. So this approach won't cut it.
There are other approaches in C++, of course. For example, I recently found the
Boost Lambda Library which
covers at least parts of what I'm after. At first sight, however, I'm not
too sure its syntax is for me. I also hear that GCC implements
nested functions:
typedef void (*FNC)(void);
FNC getFNC(void)
{
int x = 42;
void foo(void)
{
printf("now in foo, x=%d\n", x);
}
return foo;
}
int main(void)
{
FNC fnc = getFNC();
fnc();
return 0;
}
Unfortunately, extensions like this didn't make it into the standards so far.
So let's move on to greener pastures. Next stop:
How anonymous delegates in C# 2.0 implement closures.
- Closures and Lexical Binding (Franz Lisp)
- Successful Lisp: Closures
- The Idiot's Guide to Special Variables and Lexical Closures
Fight globalization! (18 Feb 2006)
defvar and
defparameter - but this way, the variable not only becomes global,
but also special. They are probably called special because of
the special effects that they display - see my blog entry for an
idea of the confusion this caused to a simple-minded C++ programmer (me).
Most of the time, I would use defvar to emulate the effect of a
"file-global" static variable in C++, and fortunately, this can be
implemented in a much cleaner fashion using a let statement
at the right spot. Example:
// C++, file foobar.C
static int globalFoo = 42;
int foobar(void)
{
return globalFoo * globalFoo;
}
int foobar2(int newVal)
{
globalFoo = newVal;
}
;; Lisp
(let ((globalFoo 42))
(defun foobar1()
(* globalFoo globalFoo))
(defun foobar2(newVal)
(setf globalFoo newVal))
)
The let statement establishes a binding for globalFoo which is only
accessible within foobar1 and foobar2. This is even better than
a static global variable in C++ at file level, because this way precisely
the functions which actually have a business with globalFoo are
able to use it; the functions foobar1 and foobar2 now share a
variable. We don't have to declare a global
variable anymore and thereby achieve better encapsulation and at the same
time avoid special variables with their amusing special effects. Life is good!
This introduces another interesting concept in Lisp: Closures,
i.e. functions with references to variables in their lexical context.
More on this hopefully soon.
I'm so special (11 Feb 2006)
int fortytwo = 42;
int shatter_illusions(void)
{
return fortytwo;
}
void quelle_surprise(void)
{
int fortytwo = 4711;
printf("shatter_illusions returns %d\n", shatter_illusions());
}
A seasoned C or C++ programmer will parse this code with his eyes shut and tell
you immediately that quelle_surprise will print "42" because shatter_illusions()
refers to the global definition of fortytwo.
Meanwhile, back in the parentheses jungle:
(defvar fortytwo 42)
(defun shatter-illusions()
fortytwo)
(defun quelle-surprise()
(let ((fortytwo 4711))
(format t "shatter-illusions returns ~A~%" (shatter-illusions))))
To a C++ programmer, this looks like a verbatim transformation of the code above
into Lisp syntax, and he will therefore assume that the code will still answer "42".
But it doesn't: quelle-surprise thinks the right answer is "4711"!
Subtleties aside, the value of Lisp variables with lexical binding is determined
by the lexical structure of the code, i.e. how forms are nested in each other.
Most of the time, let
is used to establish a lexical binding for a variable.
Variables which are dynamically bound lead a more interesting life: Their
value is also determined by how forms call each other at runtime.
The defvar
statement above both binds fortytwo to a value of 42 and declares the variable as
dynamic or special, i.e. as a variable with dynamic binding. Even if code
is executed which usually would bind the variable lexically, such as
a let form, the variable will in fact retain its dynamic binding.
"Huh? What did you say?"
-
defvardeclaresfortytwoas dynamic and binds it to a value of 42. - The
letstatement inquelle-surprisebindsfortytwoto a value of 4711, but does not change the type of binding! Hence,fortytwostill has dynamic binding which was previously established bydefvar. This is true even thoughletusually always creates a lexical binding. -
shatter-illusions, when called, inherits the dynamic bindings of the calling code; hence,fortytwowill still have a value of 4711!
defvar as follows:
(defmacro defvar (var &optional (form nil form-sp) doc-string)
`(progn (si:make-special ',var)
,(if (and doc-string *include-documentation*)
`(si:putprop ',var ,doc-string 'variable-documentation))
,(if form-sp
`(or (boundp ',var)
(setq ,var ,form)))
',var))
In the highlighted form, the variable name is declared as special,
which is equivalent with dynamic binding in Lisp.
This effect is quite surprising for a C++ programmer. I work with both Lisp and
C++, switching back and forth several times a day, so I try to minimize
the number of surprises a much as I can. Hence, I usually stay away from
special/dynamic Lisp variables, i.e. I tend to avoid defvar and friends
and only use them where they are really required.
Unfortunately, defvar and defparameter are often recommended in Lisp
tutorials to declare global variables. Even in these enlightened
times, there's still an occasional need for a global variable, and if
you follow the usual examples out there, you'll be tempted to quickly add a
defvar to get the job done. Except that now you've got a dynamically bound
variable without even really knowing it, and if you expected this variable
to behave like a global variable in C++, you're in for a surprise:
> (print fortytwo) 42 42 > (quelle-surprise) shatter-illusions returns 4711 NIL > (shatter-illusions) 42 > (print fortytwo) 42 42So you call
shatter-illusions once through quelle-surprise, and it tells
you that the value of the variable fortytwo, which is supposedly global,
is 4711. And then you call the same function again, only directly, and it
will tell you that this time fortytwo is 42.
The above code violates a very useful convention in Lisp programming which
suggests to mark global variables with asterisks
(*fortytwo*). This, along with the guideline that global variables should
only be modified using setq and setf rather than let, will avoid
most puzzling situations
like the above. Still, I have been confused by the dynamic "side-effect"
of global variables declared by defvar often enough now that I made it
a habit to question any defvar declarations I see in Lisp code.
More on avoiding global dynamic variables next time.
Should Lisp programmers be slapped in public? (17.1.2006)
After fixing a nasty bug today, I let off some steam by surfing the 'net for fun stuff and new developments. For instance, Bjarne Stroustrup recently reported on the plans for C++0x. I like most of the stuff he presents, but still was left disturbingly unimpressed with it. Maybe it's just a sign of age, but somehow I am not really thrilled anymore by a programming language standard scheduled for 2008 which, for the first time in the history of the language, includes something as basic as a hashtable. Yes, I know that pretty much all the major STL implementations already have hashtable equivalents, so it's not a real issue in practice. And yes, there are other very interesting concepts in the standard which make a lot of sense. Still - I used to be a C++ bigot, but I feel the zeal is wearing off; is that love affair over? Confused and bewildered, I surf some other direction, but only to have Sriram Krishnan explain to me that Lisp is sin. Oh great. I happen to like Lisp a lot - do I really deserve another slap in the face on the same day? But Sriram doesn't really flame us Lisp geeks; quite to the contrary. He is a programmer at Microsoft and obviously strongly impressed by Lisp as a language. His blog entry illustrates how Lisp influenced recent developments in C# - and looks at reasons why Lisp isn't as successful as many people think it should be. Meanwhile, back in the C++ jungle: Those concepts are actually quite clever, and solve an important problem in using C++ templates. In a way, C++ templates use what elsewhere is called duck typing. Why do I say this? Because the types passed to a template are checked implicitly by the template implementation rather than its declaration. If the template implementation says f = 0 andf is a template
parameter, then the template assumes that f provides an assignment
operator - otherwise the code simply won't compile. (The difference
to duck typing in its original sense is that we're talking about
compile-time checks here, not dynamic function call resolution at run-time.)
Hence, templates do not require types to derive from certain classes or
interfaces, which is particularly important when using templates for primitive
types (such as int or float). However, when the type check fails,
you'll drown in error messages which are cryptic enough to violate
the Geneva convention. To fix the error, the user of a template often
has to inspect the implementation of the template to understand
what's going on. Not exactly what they call encapsulation.
Generics in .NET improve on this by specifying constraints explicitly:
static void Foobar<T>(IFun<T> fun) where T : IFunny<T>
{
... function definition ...
}
T is required to implement IFunny. If it doesn't, the compiler will
tell you that T ain't funny at all, and that's that. No need to dig
into the implementation details of the generic function.
C++ concepts extend this idea: You can specify pretty arbitrary restrictions
on the type. An example from Stroustrup's and Dos Reis' paper:
concept Assignable<typename T, typename U=T> {
Var<T> a;
Var<const U> b;
a = b;
};
;; using this in a template definition:
template <typename T, typename U>
where Assignable<T, U>
... template definition ...
So if T and U fit into the Assignable concept, the compiler will
accept them as parameters of the template. This is cute: In true C++
tradition, this provides maximum flexibility and performance,
but solves the original problem.
Still, that C# code is much easier on the eye...
Revision: r1.29 - 09 Mar 2016 - 07:41 - ClausBrod